Learning Latent Plans
from Play
Abstract
We propose learning from teleoperated play data as a way to scale up multi-task robotic skill learning. Learning from play (LfP) offers three main advantages: 1) It is cheap. Large amounts of play data can be collected quickly as it does not require scene staging, task segmenting, or resetting to an initial state. 2) It is general. It contains both functional and non-functional behavior, relaxing the need for a predefined task distribution. 3) It is rich. Play involves repeated, varied behavior and naturally leads to high coverage of the possible interaction space. These properties distinguish play from expert demonstrations, which are rich, but expensive, and scripted unattended data collection, which is cheap, but insufficiently rich. Variety in play, however, presents a multimodality challenge to methods seeking to learn control on top. To this end, we introduce Play-LMP, a method designed to handle variability in the LfP setting by organizing it in an embedding space. Play-LMP jointly learns 1) reusable latent plan representations unsupervised from play data and 2) a single goal-conditioned policy capable of decoding inferred plans to achieve user-specified tasks. We show empirically that Play-LMP, despite not being trained on task-specific data, is capable of generalizing to 18 complex user-specified manipulation tasks with average success of 85.5%, outperforming individual models trained on expert demonstrations (success of 70.3%). Furthermore, we find that play-supervised models, unlike their expert-trained counterparts, 1) are more robust to perturbations and 2) exhibit retrying-till-success. Finally, despite never being trained with task labels, we find that our agent learns to organize its latent plan space around functional tasks.

Introduction
There has been significant recent progress showing that robots can be trained to be competent specialists, learning individual skills like grasping (
Learning from play is a fundamental and general method humans use to acquire a repertoire of complex skills and behaviors (
What is play?
Developmental psychologists and animal behaviorists have offered multiple definitions
Play-supervised Robotic Skill Learning:
In this work, we propose learning from play data (LfP), or "play-supervision", as a way to scale up multi-task robotic skill learning. We intend to learn goal-conditioned control on top of a large collection of unscripted robot play data.
But how do we define and implement robotic play, with all the same crucial properties of play previously identified? Voluntary and varied object interaction could in principle be collected by any agent equipped with 1) curiosity, boredom, or some intrinsic motivation drive
Instead, we collect a robot play dataset by allowing a user to teleoperate the robot in a playground environment, interacting with all the objects available in as many ways that they can think of. A human operator provides the necessary properties of curiosity, boredom, and affordance priors to guide rich object play. Human exploration and domain knowledge allow us to avoid the question of learning how to play, and rather focus entirely on what can be learned from play.
We show examples of the play data fed into our system in Figure 3. We underline that this data is not task specific, but rather intends to cover as much as possible of the full object interaction space allowed by the environment. Play is typically characterized along object, locomotor, and social dimensions (
Benefits of Play Data For Robotics Supervision of complex robotic skills by humans is possible, but expensive. In the learning from demonstration (LfD) setting, one can collect expert teleoperation demonstrations for each skill (Figure 4.) and train the robot to imitate the behavior. This first requires one to come up with a rigid, constrained and discrete definition of each skill that is important. If a slight variation of the skill is needed, e.g. opening a drawer by grasping the handle from the top down rather than bottom up, an entirely new set of demonstrations might be required. Additionally, if the agent is expected to compose multiple tasks in a row, e.g. opening a drawer, placing an object inside, and closing it, the researcher may need to collect demonstrations of transitions between all pairs of skills. In short, achieving flexible multi-task skill learning in an LfD setting would require a substantial and expensive human effort.
A number of recent works have attempted to sidestep the expensive demonstration effort, learning single or multi-task robotic control from unattended, scripted data collection (
In summary, if a robot needs to perform multiple complex tasks, expert demonstrations can be sufficiently rich, but are not scalable, and scripted collection is highly scalable, but not sufficiently rich. Instead, we argue that data collected from a user playing through teleoperation (LfP), is both scalable and complex enough to form the basis for large scale multi-task robotic skill learning:
- Play data is cheap. Teleoperation play data involves no scene staging, no task segmenting, and no resetting the scene to an initial state. This means it can be collected in large quantities quickly and cheaply. This represents a much more scalable alternative to segmented task demonstrations, the conventional inputs to imitation learning algorithms (an example of which is shown in Figure 4.) which must be staged, segmented, and reset.
- Play data is general. Play relaxes the need for a discrete, predefined task distribution. Instead play contains a continuum of behaviors, functional and non-functional.
- Play data is rich. The "repeat but varied" and "means over ends" properties of play naturally lead to high coverage of the possible interaction space. Since the behavior is driven by the curiosity and the boredom of the operator, it is expected to be naturally diverse (an operator will get bored opening a door the same way every time, and might try different behaviors). Furthermore, play follows exploration, and is guided by rich object attribute and affordance knowledge. This means play behavior should preserve this attribute knowledge, e.g. stacking cups, squeezing a toy, or rolling a ball. This represents a much more complex and discriminate set of interactions than what is typically available in a scripted robotic collection setting, which tends to yield indiscriminate pushing or object dragging.
In summary, we argue (and will show empirically) that play data strikes a good balance on the cost-richness tradeoff: it is highly rich, containing repetition of complex, prior-guided behaviors and many different ways of achieving the same outcome. It is also cheap, since it can be collected continuously without upfront task definition, scene staging or resetting.
Self-supervising control on top of play data Our aim in this work is to make it feasible to learn a general-purpose control policy: a policy that can flexibly achieve a wide range of complex user-specified tasks, using as inputs only inexpensive play data with no predetermined constraints. We rely on a simple structure in the data to provide self-supervision for training such policies: a random sequence of state-actions extracted from play memory describes exactly how the robot got from a particular initial state to a particular final state. This provides a synthetic labelling to train a general goal-conditioned policy, by treating the initial state of the sequence as "current state", the final state as "goal state", and the actions taken as the targets to reproduce. Furthermore, as shown in Figure 3, even though play data in general is considered "incompletely functional", subsequences mined from play data can be considered to be a noisy, but plentiful source of non-expert functional demonstrations.
Note that in this context, "self-supervision" refers to the autonomous labeling scheme for a supervised training of goal-conditioned policies, not unattended data collection. Specifically, it is not to be confused with recent "self-supervised robotics" work, where unattended, scripted robotic data collection is used to learn skills such as grasping
Organizing play behavior in a latent plan space Play, by definition, is highly varied, containing repeated, non-stereotyped object interaction. Intuitively, there are many ways of achieving the same outcome in a scene--for example opening a door quickly or slowly, grasping the top of the handle or the bottom of the handle--and an agent or operator playing in a scene should explore them all. This presents a multimodal representation learning challenge: policies must be expressive enough to model all the possible solutions to a given goal. Our approach, described in the section titled "Plan Proposer", models this variation explicitly, by learning to recognize a repertoire of reusable behaviors from play unsupervised and organize them in an embedding space. We can think of a single point in this space as representing an entire behavior our agent executed to get from a particular current state to a particular goal state. Local regions should correspond to distinct solutions to the same task. The motivation is to make learning goal-conditioned policies substantially easier: policies no longer need to encode the full knowledge of how to to traverse state space, rather they just need to learn how to accurately decode reusable latent plans.
In this paper, we introduce the following contributions:
- Learning from play (LfP), or "play-supervision", a paradigm for scaling up multi-task robotic skill learning by self-supervising on cheap and rich user teleoperated play data. We show empirically its benefits over learning from segmented demonstrations (LfD), especially in regards to scalability, robustness to perturbations, and failure recovery.
- Play-LMP, a method that jointly learns 1) reusable latent plan representations from play data and 2) goal-conditioned control capable of generalizing to a wide variety of complex user-specified manipulation tasks.
Method
Play data
Consider play data, an unbounded sequence of states and actions corresponding to voluntary, repeated, non-stereotyped object interaction between an agent and it's environment.
In our experiments, we define play data as the states and actions logged during human play teleoperation of a robot in a playground environment. Find an example of such data in Figure 3.

Play-LMP As described earlier, play is characterized as repeated object interaction that cannot be rigidly stereotyped. In this way, play can be expected to contain multiple ways of achieving the same outcome. An operator playing in an environment with a door isn't looking for the most efficient way to open it repeatedly. They will rather, through the course of curiosity or boredom, naturally experiment with the many ways the door can be opened--fast, slow, by grasping the top of the handle, the bottom of the handle etc. Intuitively, there are many distinct behaviors that might take an agent from a particular initial state to a particular final state. The presence of multiple action trajectories for the same (current state, goal state) pair presents a challenge to models seeking to learn goal-conditioned control in the form of counteracting action labels. This can be considered a multimodal representation learning problem: policies must be powerful enough to model all possible high-level behaviors that lead to the same goal outcome.
With this motivation in mind, we introduce Play-LMP (play-supervised latent motor plans), a hierarchical latent variable model for learning goal-conditioned control. Play-LMP simultaneously learns 1) reusable latent plan representations from play data and 2) plan and goal-conditioned policies, capable of decoding learned latent plans into actions to reach user-specified goal states. We call the representation space learned by Play-LMP "latent plan space". The intent is that individual points in the space correspond to behaviors recognized during play that got the agent from some initial state to some final state. We call points in the space "latent plans" because a single point should carry the necessary information for how to act, should it find itself at some point in the future in a similar initial state, trying to reach a similar goal state. That is, the embedding space is designed for efficient reuse.
Local regions of plan space should correspond to distinct solutions to the same task. In this way, we aim for Play-LMP to explicitly model the "multiple solutions'' problem in play data, relieving the policy of that effort. That is, a policy conditioned on current state, goal state, and latent plan only needs to learn how to follow the specific plan. Ideally, latent plans provide disambiguating information to the policy, turning a multimodal representation learning problem into a unimodal one. Hence, we aim for Play-LMP to recognize a repertoire of reusable behaviors simply by passively recalling play experience, then invoke them at test time to solve user-specified tasks. Finally we note that although Play-LMP was designed to ameliorate multimodality issues in play data, it is a general self-supervised control learning method that could in principle operate on any collection of state-action sequences.
Concretely, our training method consists of three modules:
- Plan Recognizer : A stochastic sequence encoder that takes a randomly sampled play sequence as input, mapping it to a distribution in latent plan space . The motivation of this encoder is to act as "recognition" network, identifying which region of latent plan space the behavior executed during the play sequence belongs to. is used only at training time to extract latent plan representations from the unlabeled data. This can be interpreted as a learned variational posterior over latent plan states.
- Plan Proposer : A stochastic encoder taking the initial state and final state from the same sampled sequence , outputting distribution . The goal of this encoder is to represent the full distribution over behaviors that connect the current state to the goal state, potentially capturing multiple distinct solutions. This can be interpreted as a learned conditional prior.
- Goal and plan conditioned policy : A policy conditioned on the current state , goal state , and a latent plan sampled from , trained to reconstruct the actions the agent took during play to reach the goal state from the initial state, as described by inferred plan .
We now describe each of the modules in detail and the losses used to train them. For a visual description of the training procedure, see Figure 2.
Plan Recognizer Consider a sequence of state action pairs of window length sampled at random from the play dataset :
We define a stochastic sequence encoder, , referred to throughout the paper as the "plan recognizer", which takes as input and outputs a distribution over latent plans. Intuitively, the idea is for the encoder not to learn to recognize plan codes as single points, but as ellipsoidal regions in latent space, forcing the codes to fill the space rather than memorizing individual training data. We parameterize our sequence encoder with a bidirectional recurrent neural network with parameters , which produces means and variances in latent plan space from .
As is typical with training VAEs, we assume the encoder has a diagonal covariance matrix, i.e. .
Individual latent plans are sampled from this distribution at training time via the "reparameterization trick" (
Plan Proposer We also define a plan proposal network, , which maps initial state and goal state to a distribution over latent plans. The goal of this network is to output the full distribution of possible plans or behaviors that an agent could execute to get from a particular initial state to a particular goal state. We parameterize the plan encoder with a multi-layer neural network with parameters , which produces means and variances in latent plan space from the to . For simplicity, we choose a unimodal multivariate Gaussian to represent distributions in latent plan space; nothing in principle stops us from using more complicated distributions.
Similarly we assume the plan encoder has a diagonal covariance matrix, i.e. . Note that is a stochastic encoder, which outputs a distribution in the same latent plan space as . Both and are trained jointly by minimizing the KL divergence between the two distributions:
Intuitively, forces the plan distribution output by the planner to place high probability on actual latent plans recognized during play. Simultaneously it enforces a regular geometry over codes output by the plan recognizer , allowing plausible plans to be sampled at test time from regions of latent space that have high probability under the conditional prior .
Task agnostic, goal and latent plan conditioned policy Here we describe how we train our task-agnostic policy to achieve user-specified goals. Our policy , parameterized by , is an RNN that takes as input current state , goal state , and a sampled latent plan , and outputs action . The policy is trained via maximum likelihood to reconstruct the actions taken during the sequence sampled from play. To obtain action predictions at training time, we sample once from the distribution output by (which has been conditioned on the entire state-action sequence ), then for each timestep in the sequence, we compute actions from inputs , , and . The loss term corresponding to the action prediction is determined as follows:
Note that we can optionally also have the decoder output state predictions, and adds another loss term penalizing a state reconstruction loss.
As mentioned earlier, at test time is discarded and we sample from the distribution output by plan proposal network , conditioned on , as described in Section "Plan Proposal". The motivation for this architecture is to relieve the policy from having to representing multiple valid action trajectory solutions implicitly. Since processes the full state-action sequence to be reconstructed, a plan sampled from should provide disambiguating information to the policy at training time, converting a multimodal problem (learn every plan) to a unimodal one (learn to decode this specific plan).
Full objective
Following
We describe the full Play-LMP minibatch training pseudocode in Algorithm 1.

A connection to conditional variational autoencoder
Play-LMP can be interpreted as a conditional variational sequence to sequence autoencoder
Zero-shot control at test time At test time, we use the trained plan proposer , and plan and goal-conditioned policy to achieve user-specified manipulation goals.
The inputs at test time are the conventional inputs to a goal-conditioned control problem, the current environment state and goal state . For example could be the end effector resting over the table, and could be the end effector pressing the green button. Together, (, ) specify a test time manipulation task.
Our trained agent achieves goal-conditioned control as follows: 1) feed and into its trained plan proposal network , which outputs a distribution over all learned latent plans that might connect to . 2) sample a single latent plan , 3) hand (, , ) to plan and goal-conditioned policy , outputting a distribution over low-level actions. 4) Sample an action, , move to the next state , then repeat 3).
Note that during test time rollouts, we keep the input to the policy fixed over steps (matching the planning horizon it was trained with). That is, it is free to replan using the current state and fixed goal state every steps. In our experiments, our agent gets observations and takes low-level actions at 30hz. We set to 32, meaning that the agent replans at roughly hz. See Figure 5 for details.
Play-GCBC We also train a play-supervised goal conditioned policy in a similar fashion to Play-LMP, but with no explicit latent plan inference. We denote this policy by and parameterized it by .That is, we train an RNN to maximize the likelihood of an action sequence sampled from play data, given the corresponding state sequence. The policy is conditioned on current state and goal state as before. We call this \gcbc (play-supervised goal-conditioned behavioral cloning), and describe the minibatch training pseudo-code in Algorithm 2.

Experiments
In this section we describe large scale experiments designed to answer the following questions:
- Can a single play-supervised general-purpose policy generalize to a wide variety of user specified manipulation tasks, despite not being trained on task-specific data?
- If so, how do models trained on play data perform relative to strongly supervised single-purpose models trained from positive only demonstrations for each task (LfD)?
- Does training on play data result in policies that are more robust to initial state perturbation than policies trained solely on positive demonstrations?
- Does decoupling latent plan inference and plan decoding into independent problems, as is done in Play-LMP, improve performance over goal-conditioned Behavioral Cloning (Play-GCBC), which does no explicit latent plan inference?
- Does Play-LMP learn a semantically meaningful plan embedding space despite never being trained with task labels?
Multi-task Control Here we describe our multi-task robotic manipulation training and evaluation environment, designed to answer the above questions.
Training Data
An updated version of the Mujoco HAPTIX system is used to collect teleoperation demonstration data
Evaluation Tasks The 18 manipulation tasks defined for evaluation purposes and for training the supervised baseline (BC) are Grasp lift, Grasp upright, Grasp flat, Open sliding, Close sliding, Drawer, Close Drawer, Sweep object, Knock object, Push red button, Push green button, Push blue button, Rotate left, Rotate right, Sweep left, Sweep right, Put into shelf, Pull out of shelf.
Generalization from play-supervision
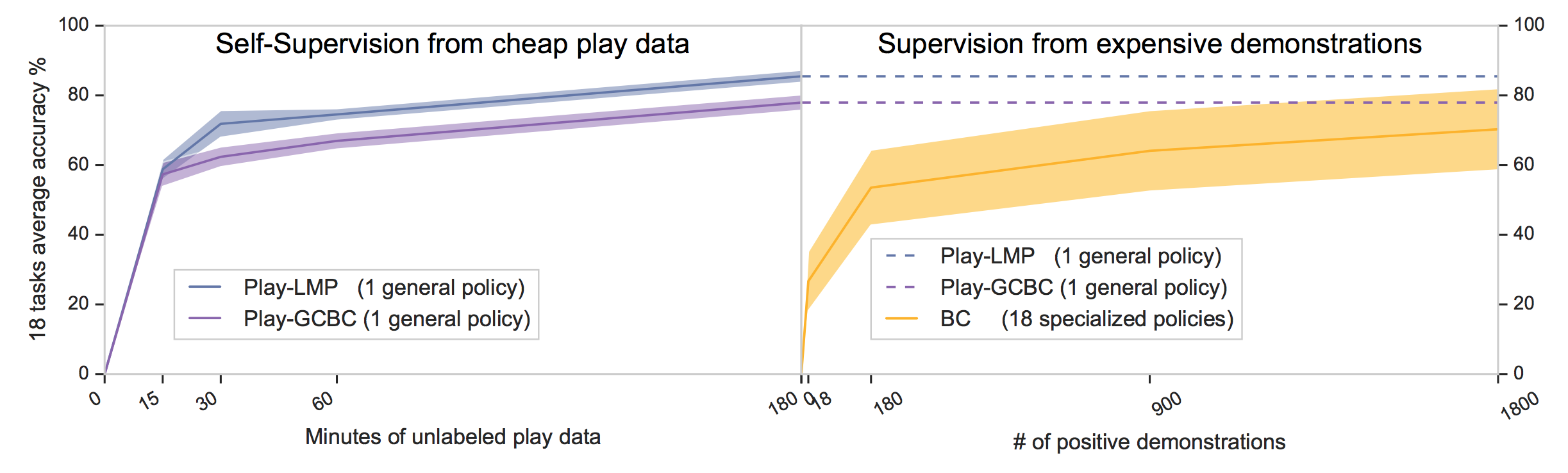
In Figure 8, we find that (Play-LMP), despite not being trained on task-specific data, generalizes to 18 user-specified manipulation tasks with an average success rate of 85.5%. This outperforms a collection of single-task expert models trained entirely on segmented positive task demonstrations (BC), who reach an average 70.3%. See examples of Play-LMP success runs in Figure 7 and failures in Figure 9.
The value of latent planning Additionally, we find that endowing play-supervised models with latent plan inference helps generalization to downstream tasks, with Play-LMP significantly outperforming Play-GCBC (average success of 85.5% vs. 78.4% respectively). Results are summarized in Figure 8.
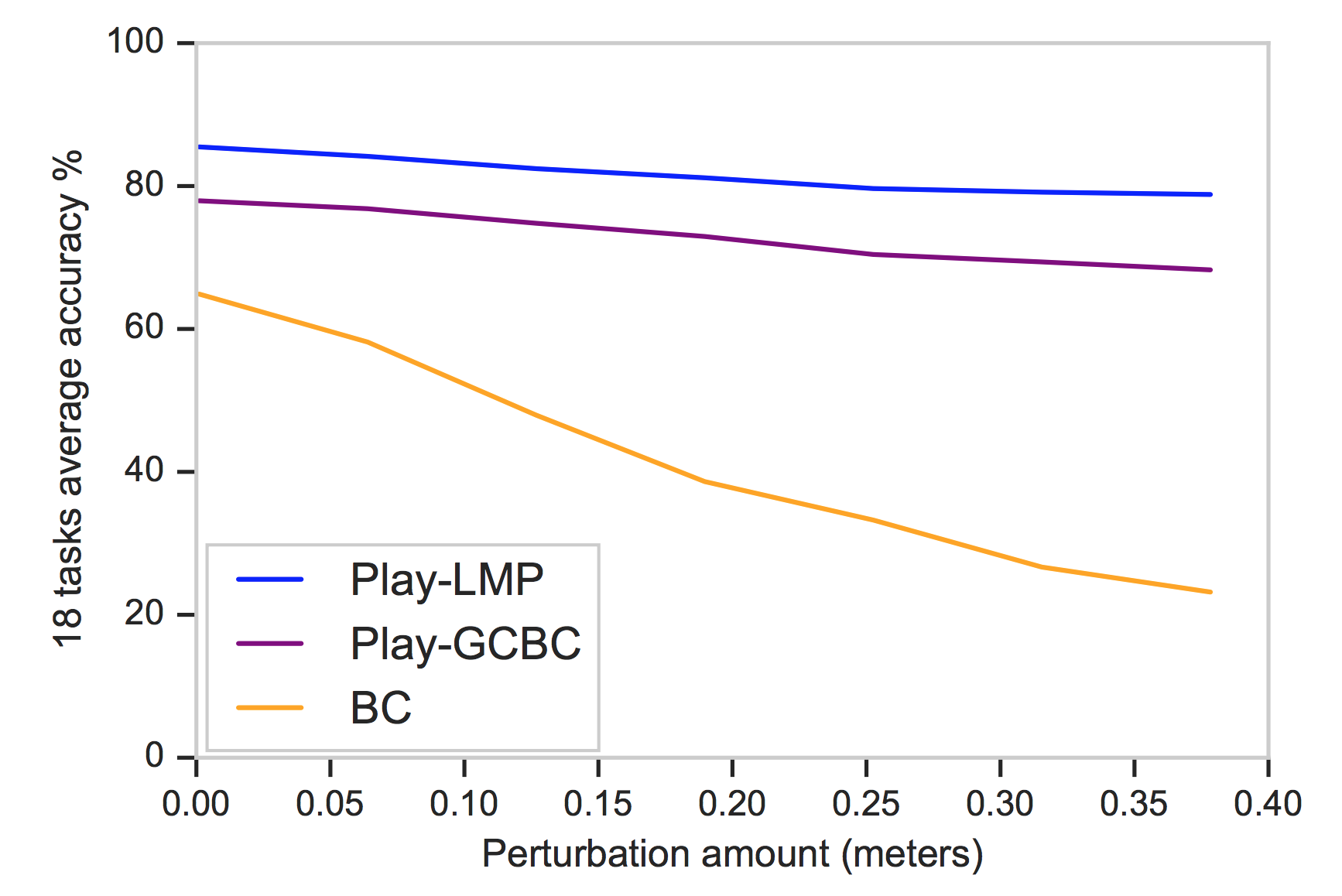
Robustness
In Figure 10, we see how robust each model is to variations in the environment at test time. To do so, prior to executing trained policies, we perturb the initial position of the robot end effector. We find that the performance of policies trained solely from positive demonstration degrades quickly as the norm of the perturbation increases, and in contrast, models trained on play data are able to robust to the perturbation. We attribute this behavior to the well-studied "distribution drift" problem in imitation learning (
Discussion
Discovering tasks unsupervised Here we investigate the latent plan spaced learned by Play-LMP, seeing whether or not it is capable of encoding task information despite never being trained with task labels. In Figure 11, we embed 512 randomly selected windows from the play dataset as well as all validation task demonstrations, using the trained plan recognition model. Surprisingly, we find that despite never being trained explicitly with task labels, Play-LMP appears to organize its latent plan space functionally. E.g. we find certain regions of space all correspond to drawer manipulation, while other regions correspond to button manipulation.

Emergent Retrying We find qualitative evidence that play-supervised models make multiple attempts to retry the task after initial failure. In Figure 12, we see examples of where our Play-LMP model makes multiple attempts before finally achieving a task. Similarly, we see that the Play-LMP model, tasked with picking up an upright object, moves to successfully pick up the object it initially had knocked over. We find that this behavior does not emerge in models trained solely on expert demonstrations. We posit that the unique "coverage" and "incompletely functional" properties of play lend support to this behavior. A long, diverse play dataset covers many transitions between arbitrary points in state space. We hypothesize despite initial errors at test time lead the agent off track, it might still have (current state, goal state) support in a play dataset to allowing a replanning mechanism to succeed. Furthermore, the behavior is "incompletely functional"--an operator might be picking a block up out of a drawer, accidentally drop it, then pick it right back up. This behavior naturally contains information on how to recover from, say, a "pick and place" task. This would be discarded from an expert demonstration dataset, but not a play dataset.
Task Composition Additionally, we show that the Play-LMP agent is capable of composing multiple behaviors learned during play (e.g. grasping and dropping) into complex, long range behaviors (e.g. grasp an object, lift it, then drop it in the trash). In figure 13 we show examples of 2-task composition. In Figure 1, we show Play-LMP accomplishing 8 tasks in a row. Here we provide the agent with a series of goal states to achieve. This kind of task composition requires being able to transition between arbitrary tasks, something which we believe play-supervision is particularly suited for, since it contains many of these "non-functional", but nevertheless important transition sequences.
Limitations
At present all models and baselines are trained using ground truth state, i.e. full pose of objects, as observations. Our aim in future work is to take raw perceptual observations as inputs. Like other methods training goal-conditioned policies, we assume tasks important to a user can be described using a single goal state. This is overly limiting in cases where a user would like to specify how she wants the agent to do a task, as well as the desired outcome, e.g. "open the drawer slowly." As mentioned earlier, we could in principle use the trained sequence encoder to perform this type of full sequence imitation. We hope to explore this in future work. Additionally, we make the assumption that play data is not overly imbalanced with regards to one object interaction versus another. That is, we assume the operator does not simply choose to play with one object in the environment and never the others. This is likely a brittle assumption in the context of lifelong learning, where an agent might prefer certain play interactions over others. In future work, we look to relax this constraint. Finally, we use parameterize the outputs of both and as simple unimodal gaussian distributions for simplicity, potentially limiting the expressiveness of our latent plan space. Since Play-LMP can be interepreted as a conditional variational autoencoder, we might in future work consider experimenting with lessons learned from the variational autoencoder literature, for example more flexible variational posteriors (
Related Work
Robotic learning methods generally require some form of supervision to acquire behavioral skills--conventionally, this supervision either consists of a cost or reward signal, as in reinforcement learning
In order to distill non-task-specific experience into a general-purpose policy, we set up our model to be conditioned on the user-specified goal. Goal conditioned policies have been explored extensively in the literature for reinforcement learning
Our work on learning latent plans is most related to
Our self-supervised learning method for learning latent plans relates to other works in self-supervised representation learning from sequences
Lastly, our work is related to prior research on few-shot learning of skills from demonstrations
Conclusion In this work, we emphasize the benefits of training a single, task-agnostic, goal-conditioned policy on unstructured, unsegmented play data, as opposed to training individual models from scratch for each task. We stress that play data strikes a good balance on the cost-richness tradeoff, compared to expensive expert demonstrations and insufficiently rich scripted collection. We introduce a novel self-supervised plan representation learning and goal-conditioned policy learning algorithm, Play-LMP, designed to scale to a difficult behavioral cloning regime with large amount of natural variability in the data. Surprisingly we find that its latent plan space learns to embed task semantics despite never being trained with task labels. Finally we find that models trained on play data are far more robust to perturbation than models trained solely on positive demonstrations, and exhibit natural failure recovery despite not being trained explicitly to do so.